

Una visión más extensa de lo que requieren los proyectos de datos puede ayudar a las organizaciones a obtener más valor de los mismos, según explican Dale MacDonald, Margarita Młodziejewska, Aziz Shaikh y Henning Soller, de McKinsey & Company, en el informe “Realizing more value from data projects”.
La sabiduría tradicional sostiene que capturar el valor total de los datos comienza con la identificación de los casos de uso adecuados. No hay duda de que la selección adecuada de casos de uso y el nivel adecuado de propiedad por parte del negocio son esenciales para crear valor real a partir de los activos de datos de una empresa. Sin embargo, los enfoques basados exclusivamente en casos de uso individuales a menudo pasan por alto la importancia de crear los habilitadores tecnológicos adecuados. Muchos proyectos de datos se diseñan e implementan para satisfacer una necesidad aguda, pero a menudo no incluyen -o retrasan la consideración de- características o elementos de diseño que son cruciales para la integración y el funcionamiento a escala. Como resultado, esta forma de trabajar a menudo añade costes organizativos y financieros una vez que se implementa el caso de uso inicial.
“Si hacemos A, obtendremos el beneficio B” es un enfoque lógico en la mayoría de las situaciones, pero no tanto en los proyectos de datos. De hecho, este enfoque modular en lugar de sistémico o de visión global con frecuencia conduce a oportunidades perdidas y costes continuos.
En cambio, las inversiones más expansivas en proyectos de datos pueden ofrecer importantes beneficios. La experiencia de los autores indica que la implementación adecuada de las inversiones en toda la cadena de valor de los datos podría reducir el tiempo de ejecución de los casos de uso entre 3 y 6 meses y el coste total de propiedad de los datos, entre un 10% y un 20%.
En esta publicación, McKinsey & Company se enfoca en los habilitadores tecnológicos necesarios para obtener valor de los datos. Los autores analizan las formas habituales en las que las organizaciones pueden mejorar el valor extraído de los datos, identifican antipatrones típicos (respuestas a problemas recurrentes que suelen ser ineficaces y posiblemente contraproducentes) y describen varias acciones que se deben tomar en consideración antes de ampliar los esfuerzos relacionados con los datos.
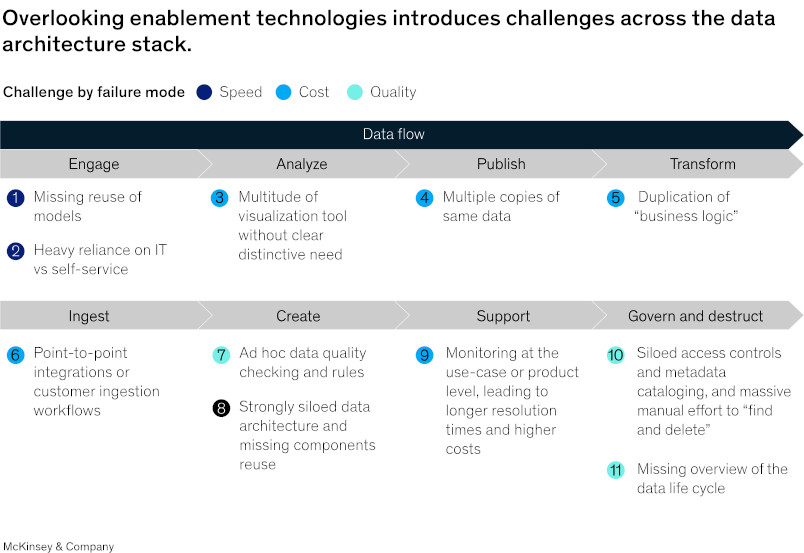
Oportunidades perdidas por enfocarse en casos de uso específicos
El valor total de los proyectos de datos tiende a proceder más de sinergias con capacidades dentro del sistema y en combinación con otros datos del sistema y menos de un resultado específico. McKinsey & Company pone el ejemplo de un minorista que desea utilizar datos para desarrollar perfiles de clientes. ¿Debería vender esa información a organizaciones externas o utilizarla para impulsar ventas adicionales para sí mismo? El valor del proyecto de datos sería lineal si los datos se vendieran como un producto, pero su valor podría ser exponencial si los datos se utilizaran junto con el sistema de datos general del minorista para generar más ventas. El uso interno de los datos también los mantendría fuera del alcance de los competidores.
No tomar en consideración los casos de uso relevantes puede llevar a perder oportunidades. Por ejemplo, McKinsey & Company ha observado a bancos desarrollar su arquitectura objetivo y su escenario de datos sin tener en cuenta los casos de uso comerciales reales. Como resultado, la plataforma no se podía utilizar para los casos de uso avanzados de analítica y riesgo, que habrían sido más útiles desde el punto de vista comercial.
Las oportunidades perdidas también pueden derivarse de la falta de automatizaciones para reducir las tareas manuales y de habilitadores que permitan la reutilización de modelos y datos. Estas consideraciones y componentes a menudo no se priorizan durante los procesos de valoración estándar, porque son difíciles de operar correctamente. No obstante, son fundamentales para un ecosistema de datos eficaz. Deben tenerse en cuenta las consecuencias: no priorizar la infraestructura escalable limita la capacidad de una organización a la hora de satisfacer las necesidades cambiantes y requiere que los proyectos se refactoricen en algún momento. No abordar la capacidad de mantenimiento desde el comienzo tiende a provocar una repetición del trabajo evitable y un mantenimiento continuo que no crea nuevo valor para la organización. Pasar por alto la automatización de las tareas de calidad y estandarización de los datos introduce el riesgo de costosos errores manuales. Por último, no configurar los sistemas de gobernanza y monitorización adecuados provoca el riesgo de que se produzcan violaciones de datos y multas que pueden poner en peligro la salud del proyecto y de la organización en general.
En otras palabras, no priorizar estos componentes fundamentales limita el valor que se puede extraer de los proyectos de datos, ralentiza la extracción de valor y hace que la sustitución y las actualizaciones de estos componentes sean más difíciles y costosas a medida que pasa el tiempo. Los sistemas resultantes pueden ser capaces de lograr objetivos de proyectos individuales, pero es poco probable que creen valor a largo plazo, al menos en comparación con los sistemas de datos diseñados teniendo en cuenta la integración.
Costes continuos
Además de las oportunidades perdidas, centrarse en casos de uso individuales en lugar de en un ecosistema más amplio de datos suele generar costes continuos y una deuda técnica sustancial. La cantidad de valor que se pierde en forma de costes continuos evitables es opaca para la mayoría de las organizaciones. Desde la perspectiva del ecosistema, las cargas de trabajo evitables son un subproducto del enfoque centrado en los casos de uso para los proyectos de datos.
Los costes más visibles están relacionados con recursos compartidos duplicados o sistemas múltiples que realizan el mismo tipo de tarea. Estos pueden ser bases de datos múltiples que alojen los mismos datos, repitiendo ensayos manuales que podrían haberse automatizado o remodelando datos del modelo de un caso de uso anterior que no era reutilizable. Este tipo de tarea evitable puede consistir en resolver el mismo problema para cada proyecto de formas específicas para cada plataforma o hacer que varios equipos resuelvan el mismo problema de forma aislada.
Los costes continuos de coordinación y mantenimiento pueden ser incluso más significativos. Cuando los proyectos de datos no se implementan con la integración en el ecosistema de mayor tamaño como parte de su diseño, a menudo es necesario deconstruir y decodificar características de sus resultados para acceder a una pieza crítica de información para una operación posterior. Debido a que estas operaciones suelen ser complejas y frágiles, la corrupción del alcance y la deuda técnica son resultados habituales. Perversamente, la deuda técnica a menudo se convierte en un argumento en contra de los esfuerzos de refactorización y mejora en etapas posteriores.
Además de generar costes continuos, estos problemas obstruyen el talento y reducen el retorno de la inversión en tecnología. La capacidad organizativa que se centra en el mantenimiento diario de sistemas múltiples no está disponible para prever y satisfacer las demandas futuras, lo que puede conducir a errores. De hecho, la experiencia de McKinsey & Company sugiere que es habitual que el 8% de la plantilla de datos de una organización se dedique a una tarea que no agrega valor, generalmente como resultado de posponer una estrategia de datos expansiva a nivel de la organización.
Para poder ver el contenido completo tienes que estar suscrito. El contenido completo para suscriptores incluye informes y artículos en profundidad




